G80 на примере MSI NX8800GTX (GeForce 8800GTX)
Восьмая серия графических карт GeForce перевернула наше представление о компьютерной графике. За счет чего получился такой большой скачок в производительности? Что принес новый API DirectX 10? Все это, а также знакомство с одной из первых GeForce 8800 GTX от компании MSI ожидает вас в данной статье
G80 на примере MSI NX8800GTX (GeForce 8800GTX)
Авторы: Рачко Антон и Алексеева Анна, *Cofradia Intel*Вступление
7 ноября 2006 года состоялся анонс новой видеокарты от компании NVIDIA - GeForce 8800GTX и ее упрощенной версии GeForce 8800GTS. От прошлых анонсов этот отличает то, что новый видеоускоритель приносит с собой не только увеличенную производительность, но и позволяет насладиться новым API от Microsoft - DirectX 10. Но и это далеко не все - новинка основана на унифицированной (Unified) архитектуре, позволяющей более эффективно использовать ресурсы графического процессора. Обо всем этом мы попытаемся рассказать в нашей статье.
Новая архитектура
Последние несколько лет архитектура видеокарт не претерпевала принципиальных изменений. Если говорить более конкретно, то все модификации, проводившиеся над графическими ускорителями, в основном, сводились к совершенствованию аппаратных конвейеров видеокарты. Для внесения ясности стоит описать, что же он из себя представляет. Вообще, конвейер в видеопроцессоре - есть аппаратное обеспечение для реализации обработки графики. А реализуется это в видеокартах с классической архитектурой следующим образом: сначала видеопроцессор получает от центрального процессора информацию об объекте. Для его обработки в дело вступает графический процессор, задействовав вершинный конвейер. Исходя из полученных данных, строится объект с конкретными координатами - вершины (vertex). Именно на этом этапе происходит подключение к работе шейдерных программ, постановка освещения и прочие работы с объектом. Далее смоделированные объекты объединяются в примитивы. Это этап называется сборкой (setup). Но! Это ещё не видимые объекты, а только информация о том, что объекты объединятся в какой-то примитив. Двигаясь дальше по конвейеру, информация попадает в пиксельный процессор, где происходит процесс растеризации (разбиения объекта на отдельные фрагменты- пиксели). На данном этапе определяются конечные пиксели, которые будут выведены в кадровый буфер. Над ними проводятся различные операции: затенение или освещение, текстурирование, присвоение цвета, данных о прозрачности и т.п. Здесь же, в видеокартах недавнего прошлого, к обработке бы подключились пиксельные шейдеры, работающие над специфическими параметрами: блеском, освещением, затемнением и т.д. При формировании трёхмерного изображения, которое нас и интересует, на данном этапе проходит выяснение глубины цвета каждой точки (Z- тестирование). Происходит передача информации на следующую стадию (Z- данные в Z- буфер). Следом идёт новый и заключительный этап. На нём, основываясь на информации о расположений пикселей, вычитанной из Z- буфера, происходит скрытие объектов друг относительно друга. Здесь как раз фрагменты с уже присвоенными им координатами и значениями цвета обрабатываются блоком ROP (Raster Operations). Собранные в полигоны фрагменты, состоящие после растеризации из пикселей, передаются в кадровый буфер. Откуда им уже прямая дорога на экран.
Схематически классический конвейер можно изобразить так:

Однако весь этот процесс выглядит гладким только на первый взгляд, иначе и менять то ничего не стоило бы. Беда же в том, что если появится необходимость запросить или изменить уже обрабатывающиеся данные, то придется дождаться окончания конвейера и выкачивать данные из буфера или вообще запрашивать заново с хоста. Если работать надо с поздними стадиями, то прогон всех предыдущих будет совершенно бесполезным. К тому же это тормозит работу остальных блоков. А разделение на вершинные и пиксельные процессоры ограничивает творчество разработчиков. С одной стороны нельзя переборщить с геометрическими характеристиками, с другой терять все красоты, получаемые мультитекстурированием и сложными пиксельными шейдерами. Так что революционные изменения в архитектуре видеокарт было ожидаемы.
Итак, пришла пора познакомиться с ядром G80 и DirectX 10.
Конкретно о DirectX 10
Так вот, главное достоинство DirectX 10 это унификация. По сравнению с предшественницей DirectX 9 - упрощение. Благодаря этому за тоже время выполняется б0льшее количество инструкций. И, как следствие, меньше запросов процессора к драйверу и API. Для решения проблем, которые были применительно к DirectХ 9, в новом API используется концепция потоковой обработки. Она подразумевает переориентацию пиксельного процессора на новые задачи. Напомним, что новый G80 состоит из пиксельных процессоров, которые универсальны и полностью заменяют специализированные конвейеры. Пройдя определенный этап, данные заново заводятся на обработку в тот же пиксельный процессор. Промежуточные результаты хранятся в потоковом буфере (stream buffer). Такой подход решает проблему со временем и ресурсами, которые приходилось тратить на повторное похождение всего классического конвейера. Следующим нововведением в DirectX 10 является геометрический шейдер (geometry shader). Он позволяет работать не только с отдельными вершинами, но и с целыми линиями, что является целесообразным, поскольку позволяет разгрузить центральный процессор. Также благоприятно возможности нового шейдера сказываются и на работе графического процессора, которому приходится просчитывать гораздо меньше информации. Новшество позволяет при обработке информации о, к примеру, воде, разбивать примитивы на более мелкие (тессилировать). Что приводит к увеличению реалистичности картинки. Также возможности геометрического шейдера ярко проявляются при обработке волос. К тому же при работе с физическими объектами геометрический процессор более эффективен, чем центральный, что используется в DirectX 10. Графический процессор обрабатывает физические эффекты до 10-ти раз быстрее! Например, это заметно при обработке волос.
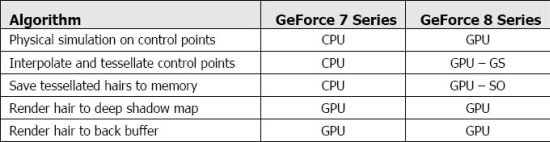
Но не стоит думать, что в DirectX 10 забыли о классических видеокартах. Они поддерживаются в полной мере. Например, благодаря вершинному текстурированию можно изменять позиции и формы объектов путем выгрузки из памяти карт смещений (displacement maps) и внесения содержащихся в них изменений в координаты вершин и примитивов. Не гонясь исключительно за нововведениями, разработчики данного API уделили достойное внимание улучшению и его функциональности по сравнению с предшественниками.
А вот и таблица, собственно говоря, изменений:
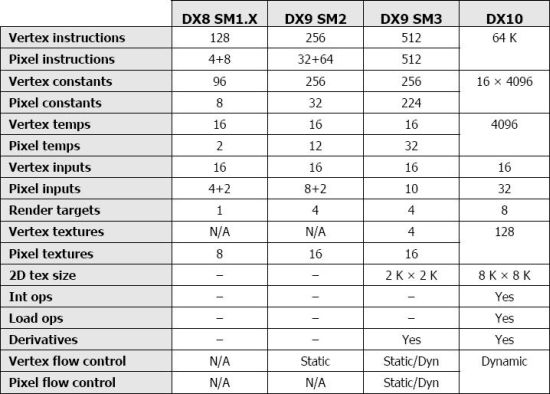
А так, как конвейером была, так конвейером со старой базой и осталась. Приходится только ждать, когда кто-нибудь покусится на более радикальные перемены.
Теперь же конкретно к ядру G80
Снова предлагаю вспомнить слово унификация, которое ещё пару раз всплывёт в статье. Советую на мгновение припасть к словарям и точно понять его смысл.
Итак, после лёгкого перерыва снова приступим всё же к концепции архитектуры NVIDIA G80. Унифицировав функциональные блоки ядра, компания добилась обработки любых видов данных без потери производительности.

В ядре G80 128 потоковых процессоров. В DirectX 10 потоки могут быть входящими и исходящими (input stream, output stream). Особенностью является то, что исходящий поток одного процессора может быть входящим другого. Благодаря вышеупомянутой унификации появляется возможность обработать информацию, полученную от одного блока другим. В отличие от классической архитектуры, которая вспоминалась выше, где требовалось ждать выполнения полного конвейера и выгрузки данных в кадровый буфер. А если у нас редкий для современных игр случай и нет необходимости в повторной обработке данных, то G80 "притворяется" классическим ядром. Правда, одновременно обрабатывает несколько наборов данных.
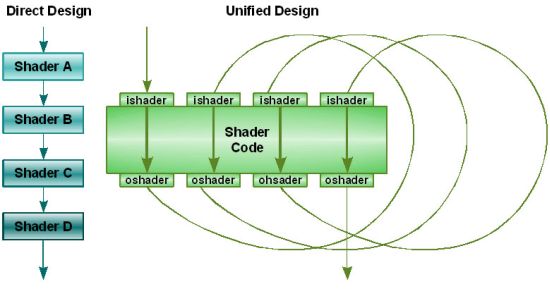
Потоковые процессоры в G80 способны заниматься обработкой как пиксельных, так и вершинных шейдеров. И этому есть достойнейшее применение. Благодаря унификации происходит динамическое распределение производительности ядра между процессорами по мере необходимости. Мы наглядно продемонстрируем, зачем унифицировать блоки. Рассмотрим это на конкретном примере.
Если при обработке основная нагрузка падает на геометрию, то геометрические процессоры ядер с фиксированным соотношением процессоров задействуют все свои резервы. А вершинные в это время, не получив задания, простаивают. А в случае же, где сложная работа с цветом, светом, блеском, прозрачностью и т.п. уже задействованы, все вершинные процессоры, зачастую оставляют геометрические без дела.

В G80 такое неравноправие устранено благодаря вышеупомянутому динамическому распределению. Когда нужно "привлечь все силы" на обработку геометрии, выделяется необходимое количество блоков для этой операции. В противном же случае необходимый максимум блоков выделяется для обработки цвета. Рационально, не правда ли?

Непосредственно конвейер с попутным разбором новинок
Первым данные о вершинах и примитивах принимает Host Inteface от графического драйвера и далее передаёт их в Input assembler. Который, считав данные из буфера хоста, переводит их в формат FP с точностью 32 бит, вместо старых 16. Это выводит детализацию на новый уровень обработки. На этом этапе каждой вершине и примитиву присваивается персональный идентификатор ID, что как раз и позволяет направлять их в дальнейшем на повторную обработку. Затем данные разделяются на потоки (streams) и передаются непосредственно в потоковые процессоры, которые их и обрабатывают. Вот о них как раз и стоит рассказать подробно. 128 процессоров ядра G80 объединены в 8 блоков. Каждому блоку был выделен кэш первого уровня. Для чего это сделано? Как раз для обеспечения потоковой обработки данных. А именно, после обработки данных одним потоковым процессором, полученная информация выгружается в кэш (тот самый stream output), откуда может быть вычитана при помощи диспетчера ветвлений GigaThread, первая версия которого появилась в GF7x, уже другим процессором для новой обработки (stream input). Минуя выгрузку в кадровый буфер и, соответственно, потерь ресурсов.

Кстати о "птичках" и новшествах. Диспетчер ветвлений GigaThread в G80 позволяет выполнять вычисление нескольких ветвлений шейдера одновременно. В отличие от предшественника, который делал это только последовательно. Более того, по утверждению NVIDIA, granularity ветвления с16 пикселями не являются проблемой. А в некоторых случаях эффективность сохраняется и при 32 пикселях. Идеальный же вариант для ядра G80 - тайтл в 4х4 когерентных пикселя. И снова к потоковым процессорам. Впервые все процессоры - скалярные. Это ожидаемый переход, который был намечен тенденциями последних лет. Инженеры NVIDIA небезосновательно решили, что 128 скалярных процессоров будут более эффективны, чем 32 векторных конвейера по 4 (3 + 1) единицы. А если понадобится произвести векторные вычисления, то векторный код переводится в скалярный непосредственно в самом ядре. С производительностью до 520 гигафлоп и работающие на частоте 1350МГц, потоковые процессоры выполняют инструкции типа MUL и MAD.
Теперь подробнее о текстурировании. Шейдерные математические операции выполняются в ядре одновременно с текстурированием. Предыдущие архитектуры не могли себе такого позволить. Вычисления прерывались, и начинались выборка и обработка текстуры, по выполнению чего снова возвращались к математике. Снова унификация.
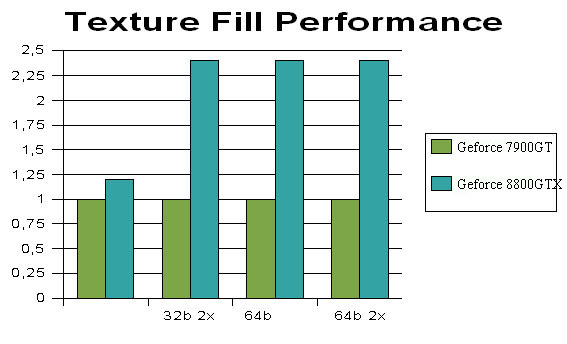
Что мы видим при сравнении скорости текстурирования представителей G70 и G80:
Изменения в следующей стадии обработки - растеризации - достойны отдельного рассмотрения - в частности, способы сглаживания картинки. Поддерживаются все существующие методы: мультисэмплинг, суперсэмплинг и адаптивное сглаживание. Введены новые профили сглаживания: 8x, 8xQ, 16x и 16xQ.
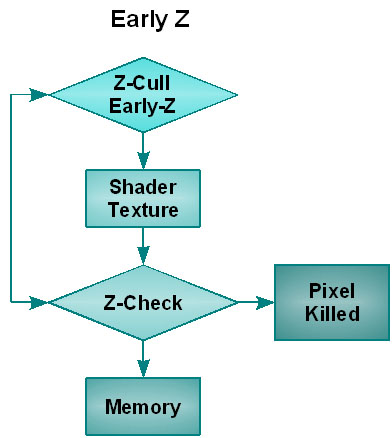
В новой архитектуре пиксели, невидимые на итоговой сцене, отсеиваются сразу же после выхода данных для пиксельной обработки, а не на этапе обработки в ROP. По идее, это должно серьёзно отразиться на производительности. В сценах с большим количеством объектов представители традиционной архитектуры просчитывают множество точек, которые уже после всех просчётов просто выбрасываются ROP. Что, как вы сами понимаете, влечёт к сильным задержкам процессора. Эту способность NVIDIA называет Early-Z, а сам метод отсеивания невидимых пикселей - Z-Cull, который уже присутствовал и в GeForce 6x. Заметим, что заявленная скорость отсеивания в 4 раза больше, чем в GeForce 7900GTX.
Итак, перед нами впервые появилась видеокарта, которая может "одной левой" обрабатывать желанную HDR-графику одновременно с полноэкранным сглаживанием. Она обрабатывает текстуры в формате FP16 и FP32, да и в обоих одновременно. Кстати, в архитектуру заложены новые технологии сжатия данных, а это поможет улучшить работу с цветом и Z-буфером.
Что же касается памяти, то ее суммарная разрядность составляет 384 бит (64 х 6). На видеокарты GeForce 8800GTX устанавливаются чипы ёмкостью 512 Мбит, что в сумме и даёт те самые 768 Мб памяти. Типы памяти, поддерживаемые устройством: GDDR1, GDDR2, GDDR3 и GDDR4. Установленные на видеокарту GeForce 8800 GTX чипы GDDR3 работают на частоте 900 МГц. Таким образом, полоса пропускания шины памяти составляет 86,4 Гб/с. А для вышеописанных stream input/ stream output каждый блок процессоров снабдили КЭШем L2. Заметим, что данный кэш заметно быстрее кадрового буфера.
Вместе с архитектурными инновациями в видеокарте GeForce 8800GTX были представлены и передовые технологии обработки графики.
Новинки обработки графики
А именно технологию Lumenex Engine, которая подразумевает под собой новые методы сглаживания (8xQ, 16xQ), выполняющиеся на скорости, сравнимой со скоростью 4xFSAA традиционным мультисэмплингом. Далеко шагнула детализация обработки FP-текстур. Теперь просчёт HDR выполняется со 128-битной точностью. А это даёт возможность различать детали как на очень тёмных, так и на очень светлых участках. Отметим, что HDR -обработка в обоих форматах (FP16, FP32) ведётся одновременно с полноэкранным мультисемплинговым сглаживанием без каких-либо ограничений. А фильтрация текстур выполняется одинаково качественно на любых объектах и под любыми углами обзора. Это явно заметно при сравнении работы старушки GeForce 7900GTX и GeForce 8800GTX:
На своём сайте NVIDIA выложила оцифрованные фотографии актрисы, телеведущей и модели в одном лице Эдриенн Керри (Adrianne Curry). Вот как раз на них и можно убедиться в какой степени технология Lumenex Engine сильна на практике:

Отмечу, что Lumenex Engine использует 10-битную адресацию цветовых координат и содержит в отображаемой палитре более миллиарда оттенков. Что в свою очередь позволяет точнее передавать цвета. А вот следующее внедрение - технология Extreme High Definition Gaming (XHD)- позволяет разойтись и геймерам. Теперь трёхмерными играми можно наслаждаться на широкоэкранных мониторах в разрешениях до 2560х1600. При этом заявляется, что чёткость изображения до 7 раз превосходит данную характеристику в видео стандарта 1080i и вдвое - 1080p. Для этого блага монитор подключается по Dual-Link DVI. Правда для хорошей производительности сама NVIDIA рекомендует массивы из двух видеокарт в SLI.
В подтверждение вышеописанного - картинка:

Следующая технология появившаяся в GeForce 8800: Quantum Effects. Это уже технология обработки физики средствами самого графического процессора. В поле действия Quantum Effects попадают взрывы, дым, огонь, столкновения мелких объектов, волосы, вода, мех. А призвана она разгрузить основной процессор и повысить реалистичность игр.
Поработала NVIDIA и на благо видео высокого разрешения. А именно внедрила технологии PureVideo и PureVideo HD. Причём если PureVideo давно уже представлено подвержено обсуждению, то PureVideo HD представлена на всеобщий смотр в одно время с выходом самой видеокарты. Акцент у новой технологии ставится на поддержку стандартов HD DVD и Blu-ray, защищённых технологией AACS. Постобработка при помощи данной технологии устраняет шумы, сглаживает картинку и позволяет провести тонкую настройку цветности в видео высокого разрешения.
Ядро содержит аппаратный декодеры видео стандартов H.264, VC-1, WMV/WMV-HD и MPEG-2 HD, что в свою очередь позволяет разгрузить центральный процессор. NVIDIA не посчитала лишним похвастаться тем, что в тестовом пакете HQV Benchmark, оценивающем производительность видеокарт в декодировании видео, GeForce 8800 получили 128 очков из 130 возможных. А это - рекорд на нынешний момент времени.
Дабы не быть голословными в хвалебных словах - сравнительная иллюстрация:

Спецификации
Видеокарта MSI NX8800GTX основана на GPU NVIDIA G80, ставшим чуть ли не синонимом DirectX 10. Новый API должен принести еще более реальную графику, а G80 с максимальной эффективностью воплотить ее в жизнь. Для этого компания NVIDIA разработала архитектуру, являющеюся, без преувеличения, революционной. Новый GPU содержит 128 независимых потоковых процессоров, способных динамически переназначаться для выполнения вершинных, пиксельных, геометрических или физических операций. В отличии от классической дискретной архитектуры, в которой для исполнения шейдера используется множество стадий конвейера в линейной последовательности, новинка исполняет шейдеры циклично. Данные проходят через процессор, результат записываются в регистр и заново поступают в тот же процессор. Процессор же в свою очередь переориентируется на выполнение новой задачи. Сравнительные характеристики приведены в таблице ниже.
Наименование характеристикATI Radeon X1950 XTXNVIDIA GeForce 7900 GTXNVIDIA GeForce 8800 GTXГрафический процессорR580+G71 G80 Техпроцесс, мкм0.09 (low-k)
Число транзисторов, Млн.384278681Частота(ы) графического(их) процессора(ов), Мгц650 (500 в 2D-режиме)675575 (1350 shader)Частота видеопамяти, Мгц2000 (1200 в 2D-режиме)12001800Объем памяти, Мб5122 x 512768Тип используемой памятиGDDR4GDDR3GDDR3Разрядность шины обмена с памятью, Bit256384ИнтерфейсPCI-Express x16
Число шейдерных пиксельных процессоров, шт.4824128Число шейдерных вершинных процессоров, шт.88Число текстурных блоков, шт.162432Число блоков растеризации (ROP’s), шт.161624Поддержка версии Pixel Shaders / Vertex Shaders3.0 / 3.04.0 / 4.0Полоса пропускания видеопамяти, Gb/s~64.0~38.4~86.4Пиковая потребляемая мощность в 3D режиме работы, W~120< 143~ 177Требования к мощности блока питания, W~500~ 500~ 450Размеры видеокарты эталонного дизайна, мм. (Д х В х Т)220 x 100 x 31230 x 100 x 38270 x 100 x 38Выходы2 x DVI (Dual-Link), TV-Out, HDTV-Out, поддержка VIVOУпаковка и комплектация
Карта поставляется в стильной картонной коробке с пластиковой ручкой.

На лицевой стороне коробки изображена сказочная девушка, основные спецификации карты и ключевые составляющие её комплектации.

На задней стороне коробке довольно подробно расписываются характеристики карты, системные требования и фирменная технология от MSI - DOT express, позволяющая автоматически разгонять видеокарту.
Помимо дополнительной и прочной коробки она упакована в пенопласт и закрыта крышкой из прозрачного пластика.
Комплектацию карты составляют:
- Инструкции по установке и эксплуатации;
- Переходник питания;
- VIVO+HDTV переходник;
- 2x DVI > D-Sub переходника;
- S-Video кабель;
- Диски с драйверами и DVD-проигрывателем;
- Бонус - полная версия игры Serious Sam 2.
В нашем случае переходник питания был всего один, хотя для работы карту нужно запитать от двух разъемов. Скорее всего, он был просто утерян, и в полной комплектации присутствует.
Внешний вид и эргономика
Карта является точной копией референсной карты от NVIDIA, отличием является лишь логотип MSI на системе охлаждения.


Карта оснащена двумя разъемами SLI.

Зачем нужен второй разъем не известно. Возможно, GF8800GTX стала первой картой с полнодуплексным SLI, либо второй разъем требуется для объединения в тендем более двух карт. 700 миллионов транзисторов дают о себе знать. Карта весьма прожорлива в плане питания, поэтому ее оснастили двумя питающими разъемами.

Если Вы не подключите один из разъемов, на карте сработает сигнализация.

Подобная система уже применялась в картах серии GF6800.
Отдельное внимание уделим габаритам карты. Без сомнения, GeForce 8800GTX является если не самой, то почти самой длинной видеокартой для PC. На следующей фотографии вместе с героиней соседствуют некогда "огромная" 3DFx Voodoo 5 5500 PCI и GeForce 7900GTX.

Для полноты картины приведем фотографию карты, установленную в тестовую материнскую плату.

Длина карты больше ширины мат. платы. Вполне вероятно, что при покупке видеокарты вам продеться докупить новый корпус.
Система охлаждения
Первым, на что обратим внимание, так это вентиляционные отверстия в окончании кулера.

Заметная, если не большая часть разогретого воздуха выходит именно в них. Что делать, инженерам приходиться адаптировать все более горячие видеокарты под уже устаревший стандарт ATX. Счастливому обладателю такой карты мы можем лишь посоветовать установить вентилятор на обдув карты, например тихоходный 120мм. Карта сложная, кулер тоже. Он не просто так крепиться 11-ю винтами.

Монолитная конструкция охлаждает процессор, память, питание и ЦАП. Последний был вынесен за пределы процессора по причине наводок.
А вот так кулер выглядит без кожуха.

Довольно просто, но очень эффективно.
Система охлаждения демонтирована и самое время посмотреть на плату "голой".
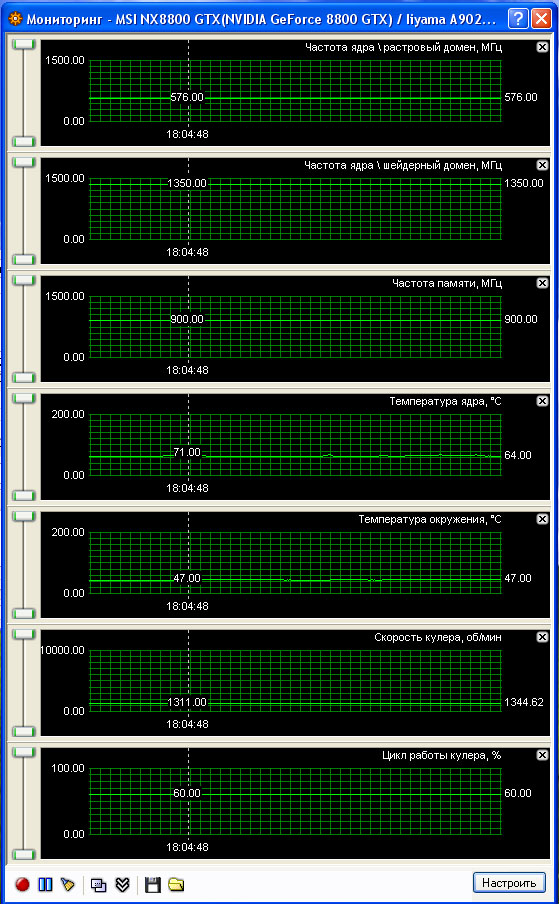
Самая большая температура ядра, зафиксированная в ходе тестов, составила 71 градус.
Плата

Размеры процессора впечатляют! Обратите внимание, NVIDIA впервые со времен GF5900 установила на GPU защитную крышку (теплораспределитель). Помимо него чип обрамлен усиливающей рамкой, призванной предотвратить повреждение кристалла и пайки. Рамка крепится при помощи 8 винтов.

Графический чип на плате имеет ревизию A2. По всей видимости, ревизии A1 стали присущи лишь инженерным образцам и не попадают на конечные решения.
Riva Tuner отображает следующую информацию:

Может показаться странным, но на картах серии 8800 применяется память DDR3. DDR4 в проекте.

Чипы памяти равноудалены от графического процессора. Общий объем видеопамяти равен 768 Мб и набран 12-ю микросхемами производства Samsung с временем выборки 1,0 нс.
Тестирование
Для тестов применялся следующий стенд:
- Процессор AMD Athlon 64 3200+@2400МГц, ядро Venice;
- Материнская плата ASUS A8N-SLI Deluxe, чипсет NVIDIA nForce 4 SLI;
- Оперативная память 2х512Мб DDR400@240МГц, тайминги 3.0-4-4-9-1T;
- Операционная система Windows XP SP2, драйвер чипсета версии 6.86.
Начнем с синтетических тестов 3D Mark.
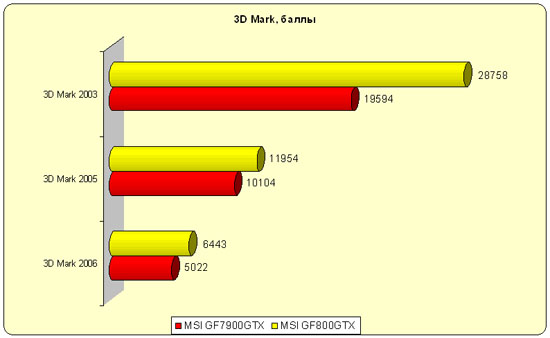
8800-я набрала много, но могла бы больше. Все уперлось в центральный процессор.
Перейдем к играм.
Тесты мы будем производить в трех разрешениях (1024 х 768, 1280х1024 и 1600x1200) в 3-х режимах (Medium (качество высоко, без AA и AF), High (качество высоко, 2xAA и 8xAF) и Ultra High (качество высоко, 4xAA и 16xAF). Игры были настроены на высокое качество.
NFS Carbon является новой и весьма требовательной игрой, что под стать мощной видеокарте. Однако когда мы ее тестировали, нас одолевал вопрос: ну что такого в этой карте? Всего-то около 50-ти кадров! Ответ на свой вопрос мы получили, протестировав соперника в лице GF7900GTX.

Обратите внимание, GF7900GTX, являющиеся и по сей день современной и производительным решением, серьезно проигрывает новинке даже в легких режимах. В тяжелых же режимах проигрыш катастрофичен, на недавнем hi-end попросту невозможно играть!
Посмотрим на более старые игры.
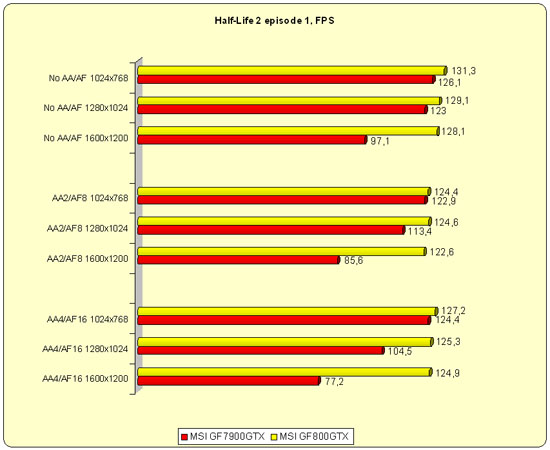
Обе карты достойно справились с игрой даже в тяжелых режимах. Только GF8800 сделал это лучше предшественника.
Посмотрим на FEAR.


Серьезный разрыв особо хорошо заметен в тяжелых режимах. Комментарии излишни.
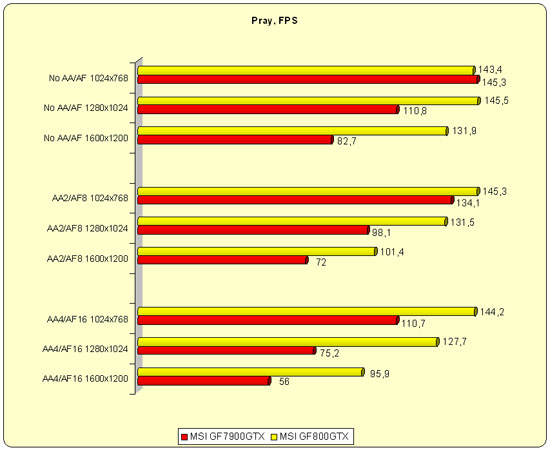
Аналогично и в игре Pray. Всю мощь новинки понимаешь только в сравнении. И не удивительно, ведь при игре на ней забываешь, что такое "тормоза", и игра уже кажетcя довольно "простой".
Выводы
Незачем расхваливать драгоценные металлы, поскольку они и так драгоценные. Аналогично получается и с GeForce 8800GTX. Даже на нашем "слабом" тестовом стенде, при использовании данной видеокарты можно с комфортом поиграть в самые современные игры. Что, кстати, доказывает рациональность покупки новинки для владельцев устаревших ПК. В купе с процессором класса Intel Core 2 новинка показала бы еще лучшие результаты.
Личная моддинг коллекция